SQL datasets
Article overview
In this article, we'll be describing the "SQL datasets" functionality that you can use in Luzmo to add datasets from your data source, using SQL statements. We'll explain what the feature is, some example use-cases where it could be useful, and how to use it:
- What are SQL datasets?
- Why use SQL datasets?
- Adding a SQL dataset & Adapting existing SQL dataset queries
- Dynamic SQL statements
What are SQL datasets?
A SQL dataset in Luzmo is similar to any other dataset, except that it's created and queried using a SQL query that you can write when adding a dataset to your account. This concept is similar to "Views" in SQL databases: virtual tables that originate from the result-set of a SQL statement.
When a SQL dataset is queried in Luzmo (e.g. in a dashboard widget), it will be referenced as a subquery in the final query sent to your data source. For example, visualizing the average value by category in a widget would result in the following final query:
SELECT
category,
AVG(value)
FROM (
-- Luzmo will reference the SQL dataset statement here
<sql_statement>
)
GROUP by
category
ORDER BY
category ASC
Why use SQL datasets?
Typically it is recommended to aim for a single source of truth, meaning you have a single data source that contains all business logic (e.g. SQL views) to ensure consistent usage across applications (see this Academy article about preparing your data for analytics). There are however some use-cases where SQL datasets defined within Luzmo could be useful:
- You want to enable Luzmo users to create their own views on the data stored in your data source, without (immediately) applying those changes in the data source itself (e.g. prejoining tables, adding calculations within the SQL, etc.).
- For specific insights, you need more complex query logic that is not (yet) available in Luzmo (e.g. complex joins, window functions, etc.)
Adding a SQL dataset
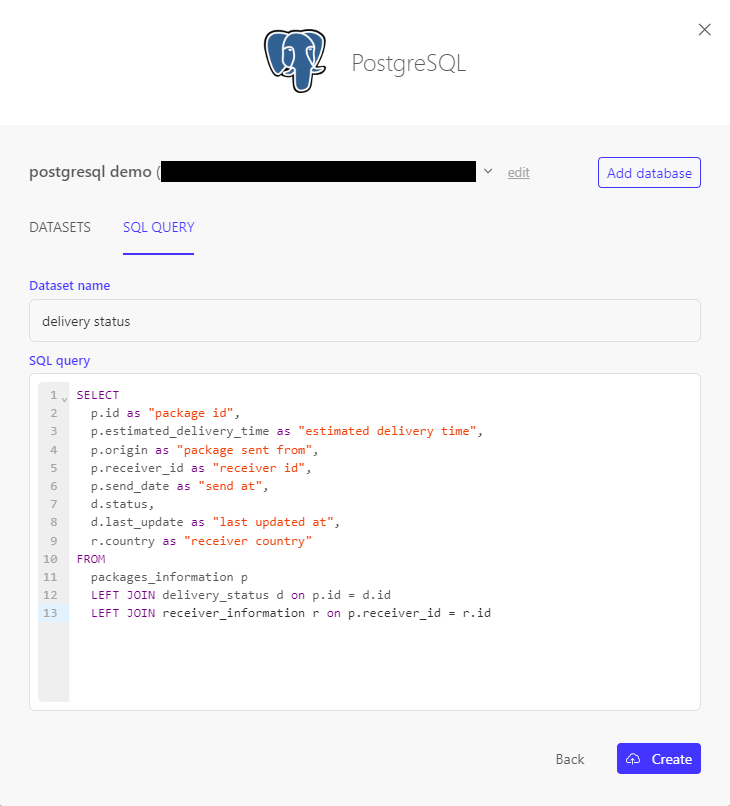
When adding a dataset from a specific Connection, you can click on the "SQL query" tab in the "Add datasets" modal to define the dataset name and SQL statement to execute.
Note that there is currently no autocompletion, as we currently do not query your data source schema upfront. However, we do highlight SQL keywords and validate the SQL query when creating the SQL dataset!
Adapting existing SQL dataset queries
If you have "owner" access to the dataset, you can go to the dataset details page to adapt the existing query (in the SQL dataset's databoard preview -> Edit details -> "Edit query" button).
Do note that changing the SQL definition in a manner which will alter the schema of the resultset, could result in breaking existing setups (dashboards, dataset links, ... ) that depend on the previous schema. We recommend avoiding breaking changes by only adding new columns instead of adapting/deleting previously accessible columns, unless you're sure the previously accessible column(s) are not referenced in existing setups!
Dynamic SQL statements
Instead of using a static SQL statement to generate the required data structure to visualize your insights, it might be interesting to dynamically alter the SQL query when embedding dashboards in your application. This could be useful in case you would like to use a (partially) different SQL statement for (specific) end-users in your application, while visualizing their insights in the same "standard" dashboard(s)! Below we provide some more details on how to parameterize a SQL dataset to allow dynamically overriding these parameter values, and how to override the complete SQL statement itself.
Parameterized SQL datasets
While creating or editing a SQL dataset, you can parameterize anything within the query by specifying {{metadata.< parameter name >|< default value >}}. The < default value > specified will be used in the SQL query, unless you override the parameter < parameter name > in the parameter_overrides of the "embed" Authorization token request (see this Academy article); in that case, we'll dynamically fill in the overridden parameter value instead of using the default value. It's important to carefully validate the parameter values to avoid SQL injection!
As a simple example, consider the following SQL dataset that exposes the data from the name and age columns of the dummy_members table by default, but the table name itself is parameterized by a parameter with name customer_members_table:
SELECT
name AS "Member name",
age AS "Member age"
FROM {{metadata.customer_members_table|dummy_members}}
To override the parameter customer_members_table defined in that SQL statement when requesting a Embed token, we can specify the following parameter_overrides:
...,
"parameter_overrides": {
"customer_members_table": "customerA_members"
}
Embedding a dashboard with such Embed key-token pair will result in dynamically referencing the customerA_members table, instead of the default dummy_members table, when querying the SQL dataset 🎉
Parameterized SQL can be used to override any part of the SQL, in above example the table queried gets dynamically determined by the parameter. In the same fashion, you can also determine which column, for example, gets queried. An example of that is available in this article showcasing how you can query a different column based on the language of a user.
Overriding the SQL statement
When requesting a Embed token for your end-users, you can dynamically override the SQL statements of one or more SQL datasets by using account_overrides (see this Academy article).Similar as above, it is important that the schema of the overridden SQL statement results in the same schema as required to query your insights (i.e. same column names and types as the initial SQL dataset).
In order to override a SQL dataset's query, you need to provide its Connection UUID and dataset UUID as keys, as shown in the example below:
...,
"account_overrides": {
"<connection_id>": {
"datasets": {
"<dataset_id>": {
"sql": "<sql_statement_with_same_resultset_schema>"
}
}
}
}